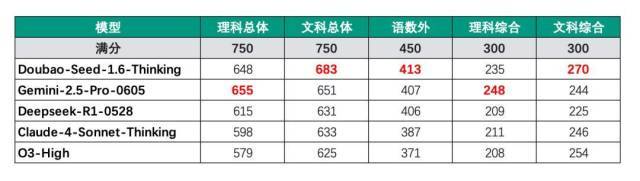
 在过去的两天中,不同领域的大学入学考试结果终于仅宣布了。现在,是时候展示世界上大型模型的第一批剧院的“大学进入结果”的时候 - 让我们首先研究一般情况(试验是由Bontedance Seed Team正式发布的):根据传统的文科和科学分部的方法,Gemini的整体科学得分是655分,在所有比赛中都有655分。杜巴(Dubao)的总体文科标记为683分,首先排名,他的总科学得分为648分,第二名。让我们看一下每个细分主题的结果:除了数学,化学和生物学外,杜巴分数仍然属于顶部,以及所有6个主题的第一名。但是,其他AI球员表演了,他们可以说,好学生的水平达到了。更令人遗憾的比赛是O3,因为它用完了中文写作问题,因此中国得分只有95点,降低整体标记。如果我们从填写申请表的角度看待这一点,因为这一范围的测试使用山东省的纸质测试,根据先前的经验,与原始分数相比,三个选定主题的标记将在一定程度上提高,尤其是在具有更困难的主题中,例如化学和物理学。除了目前相对较低的化学评分外,其他杜巴主题组合的标记可能超过690分,预计在Tsinghua大学和北京大学将受到保护。 。在对模型的一个大型模型进行大学入学评论时,如何判断分数?查看完整的积分后,许多朋友可能会想知道如何发生这个评论标记。不用担心,让我们独自研究评估标准。首先,就选择论文而言,因为当前从互联网上泄漏的大学入学评论问题是非正式的,而山东是FEW省在大学入学评估中分布了全部试验论文;因此,主要主题(即中文,数学和英语)今年使用了国家第一篇论文,而副主题则使用山东纸,总计为750分。其次,就审查方法而言,它们都通过API测试,并且没有在线查询。评分过程还指基于Pasukan在大学入学的Pasukan入口的过程,即测试整体模型功能:机器(自动审查)和手动质量检查评估了许多选项和填充问题;开放问题是在双重评估系统中实现的,两位主要的高中教师具有经验丰富的基于评论的评论,并建立了许多质量检查质量轮换。当模型进行分级时,使用了“ 3个主要主题(中文,数学,英语) + 3综合主题(科学,科学或文科)”的总方法,五个对模型进行了排名。值得一提的是,在整个评估过程中,这些模型不使用任何单词 - 优化的技术来提高模型性能,图拉德的模型要求更详细地回答,或者故意解释这是大学入学评论等。最后,在一个公平而公平的环境中,从我们刚刚显示的结果来看,与其他AIS相比,我们刚刚表明的是,我们刚刚表明的是,Gemini和Dubao取得了不错的成绩。细分的主题绩效分析并了解最终的标准,我们将继续解释AI参与者在各种主题中的表现。由于深入思考的流行,大型模型在诸如数学之类的强有力主题中的能力显然比去年好(大多数以前已经失败了),实际上每个人都得到140分。但是,在一个无严重的单选问题(国家论文1问题6)中,国内和外国大型模型陷入困境:答案provi大型模型对这个问题的限制如下:beanbao:c;双子座:b;克劳德:C; O3:C; DeepSeek:C。但是正确解决这个问题的解决方案应该是一个,因此在这里杀死了大型模型。这主要是因为问题包含图片,其中包含框架,虚线,箭头和汉字的组合。该模型将无法识别图像,这意味着他们仍然有“查看图片和说话”的空间。而且,由于结局中更加困难的问题,许多大型模型并没有完全获胜,并且经常错过证明过程,或者减少并不严格,这意味着需要加强细节。当涉及到中国的多项选择和阅读问题的两个部分时,大型模型几乎是“学术领域”,得分很高。但是,由于写作太严格,单词很冷,文章中的单词数量不符合标准(少于800个单词或超过1,200个单词),因此,一些问题也暴露在写作过程中,因为想法是不正确的,常见的字幕通常以形式出现。在书面上,这样的单词不够准确,句子略有不变,但是总体情况非常接近完美。在以下问题中,正确的答案应为C。大型模型的答案如下:beanbao:c;双子座:c;克劳德:D; O3:D; DeepSeek:D。最后,就文科而言,大型模型之间区域的差异更为明显。当外国大型模型提出政治和历史问题时,他们通常不了解经过测试的内容,并且对中国的知识点并不是很“冷”。在地理问题方面,最困难的事情是研究统计图和地形图,您应该准确地从地图中提取信息,然后对其进行研究。以上是对本综述的全面评论。除了审查今年进入国内大学的入学外,这些“参与者”还参与在第二次参加印度技术学院的第二次YU考试中 - JEE Advanced。每年数以百万计的人参加考试的第一阶段,前25万名候选人可以在第二阶段前进。它分为两场比赛,每场都有3个小时,并研究了数学,物理和化学的三个主题。该问题以图片形式显示,重点是多模式处理能力和模型的总体推理。所有这些问题都是客观的问题,每个问题都是样本5次,严格按照JEE审查规则进行评分 - 分数将正确得分,如果回答不正确,则分数将被扣除,并且不涉及格式评分标准。比较所有印度人候选人的分数,这表明第一名是332分,第10位将终止317分。值得注意的是,Beanbao和Gemini有能力进入印度的前十名:双子座在物理和化学主题中徒劳无功,而Beanbao通过5个数学学科的例子实现了完整的比赛。这是怎么做的?与去年一流大学的在线和离线水平相比,总的来说,大型模型在今年的大学入学评论问题中的表现已大大提高。那么他们如何提高自己的能力呢?让Bean Bag赢得最多的单个项目编号,以了解这一点。 Dubao Big Model 1.6系列是由Bontedance Seed Team推出的新一代通用模型,结合了多模式和深层推理能力。改进您的技术亮点可以归因于三个技巧。第一个技巧:种子构造能力的多模式融合和256K长的上下文1.6继续在稀疏MOE(混合专家模型)领域的种子1.5的技术积累,并使用23B激活参数和230b总P实践前的芳香尺寸。它的预训练过程实现了融合和延长支撑的多模式能力:阶段1:纯文本预训练。基于网页,书籍,论文,代码和其他数据作为培训的基础,它通过清洁数据,过滤,减少和征服技术与策略和模型相结合来改善数据质量和密度。第二阶段:多模式与连续训练(MMCT)混合(MMCT)将进一步增强D密度文本文本的知识和识别,增加主题,代码和识别数据的比例,同时引入视觉模态数据,以将其与高质量的文本混合。第3阶段:连续训练(LONGCT)的漫长背景通过发短信的数据来逐渐扩大模型顺序的长度,从而将最大支持长度从32K增加到256K。通过继续优化模型架构,培训和基础算法,SEED1.6的性能与种子1.5的基础相比,当参数量表接近时,基础模型显着改善,将基础用于后续训练任务。此举努力在提高准确性方面发挥了作用,例如在科学应用中了解中文阅读,英语空白和全面的OneSsemsquion,因为它们通常涉及长文本和上下文理解。第二个技巧:多模式融合思考的能力。 SEED1.6认为,延续了多个阶段的RFT(强化反馈培训)和RL(强化研究)迭代优化种子1.5思维的方法。每个RL旋转都有一个起点,最好的答案是通过多维奖励模型过滤的。与前几代相比,升级点包括:扩大计算强度和高质量的数据大小(涵盖数学,代码,拼图等领域);改善复杂问题的思考时间,VLM功能的深层集成,并提供明确的能力模型,以理解视觉效果;引入奉献精神的一致性技术,扩展模型功能而没有进一步的培训,例如,在超越AIME的高难度测试集中,推理标记增加了8分,并且性能代码性能明显优化。该功能直接对应于涉及大学入学评论的图表和公式的问题,例如数学的证明几何,物理电路图的评估,地理和其他高线解释等;它很快找到了基本参数,并在解决问题方面存在问题,以避免由于缺乏单局信息而引起的误解。第三个技巧:Autocot解决了跌倒的问题。深思熟虑取决于长床(长思维链)来增强推理的能力,但很容易导致“崩溃” - 产生大量无效令牌并增加推理的负担。因此,种子1.6-autocot提出了“动态思维能力”,提供了三种模式:全心全意,无意识和发人深省,并在RL训练中引入新的奖励功能(惩罚适当思维的下降和奖励),以实现动态压缩的cot长度。在实际试验中:在中等的非门诊任务(例如MMLU,MMLU Pro)中,COT触发率与任务难度呈正相关(MMLU触发率为37%,MMLU Pro触发率为70%);在复杂的任务(例如AIME)中,COT触发率为100%,效果与Seed1.6-Fullcot相当,证实了自适应思维的长COT推断优势的维护。以上就是为什么杜巴能够站起来回顾今年大学入学评论的整个主题的原因。但是除此之外,还有一些值得谈论的影响因素。正如我们今天提到的,阅读照片提供了巨大的比例关于化学和生物学的问题,但是由于非官方图像的清晰度不足,大多数大型模型的表现不佳。但是,GEMINI2.5-PRO-0605具有出色的多模式能力,尤其是在化学领域。但是,最近,在使用了更清晰的大学入学审查问题照片之后,Byteseed团队排练了生物学和化学的主题,对MG MGA图片组合中的图片有很高的要求。结果表明,种子1.6认为的总得分增加了约30分(科学总分为676)。交错图形和文本的示例。它表明,全模式推理(结合文本和图像)可以显着释放该模型的潜力和值得将来进行深入探索的方向。那么,您目前如何看待大型模型之战的结果呢?欢迎大家使用真实的问题尝试它们,并在Comm中留下您的感受Ent区域〜
在过去的两天中,不同领域的大学入学考试结果终于仅宣布了。现在,是时候展示世界上大型模型的第一批剧院的“大学进入结果”的时候 - 让我们首先研究一般情况(试验是由Bontedance Seed Team正式发布的):根据传统的文科和科学分部的方法,Gemini的整体科学得分是655分,在所有比赛中都有655分。杜巴(Dubao)的总体文科标记为683分,首先排名,他的总科学得分为648分,第二名。让我们看一下每个细分主题的结果:除了数学,化学和生物学外,杜巴分数仍然属于顶部,以及所有6个主题的第一名。但是,其他AI球员表演了,他们可以说,好学生的水平达到了。更令人遗憾的比赛是O3,因为它用完了中文写作问题,因此中国得分只有95点,降低整体标记。如果我们从填写申请表的角度看待这一点,因为这一范围的测试使用山东省的纸质测试,根据先前的经验,与原始分数相比,三个选定主题的标记将在一定程度上提高,尤其是在具有更困难的主题中,例如化学和物理学。除了目前相对较低的化学评分外,其他杜巴主题组合的标记可能超过690分,预计在Tsinghua大学和北京大学将受到保护。 。在对模型的一个大型模型进行大学入学评论时,如何判断分数?查看完整的积分后,许多朋友可能会想知道如何发生这个评论标记。不用担心,让我们独自研究评估标准。首先,就选择论文而言,因为当前从互联网上泄漏的大学入学评论问题是非正式的,而山东是FEW省在大学入学评估中分布了全部试验论文;因此,主要主题(即中文,数学和英语)今年使用了国家第一篇论文,而副主题则使用山东纸,总计为750分。其次,就审查方法而言,它们都通过API测试,并且没有在线查询。评分过程还指基于Pasukan在大学入学的Pasukan入口的过程,即测试整体模型功能:机器(自动审查)和手动质量检查评估了许多选项和填充问题;开放问题是在双重评估系统中实现的,两位主要的高中教师具有经验丰富的基于评论的评论,并建立了许多质量检查质量轮换。当模型进行分级时,使用了“ 3个主要主题(中文,数学,英语) + 3综合主题(科学,科学或文科)”的总方法,五个对模型进行了排名。值得一提的是,在整个评估过程中,这些模型不使用任何单词 - 优化的技术来提高模型性能,图拉德的模型要求更详细地回答,或者故意解释这是大学入学评论等。最后,在一个公平而公平的环境中,从我们刚刚显示的结果来看,与其他AIS相比,我们刚刚表明的是,我们刚刚表明的是,Gemini和Dubao取得了不错的成绩。细分的主题绩效分析并了解最终的标准,我们将继续解释AI参与者在各种主题中的表现。由于深入思考的流行,大型模型在诸如数学之类的强有力主题中的能力显然比去年好(大多数以前已经失败了),实际上每个人都得到140分。但是,在一个无严重的单选问题(国家论文1问题6)中,国内和外国大型模型陷入困境:答案provi大型模型对这个问题的限制如下:beanbao:c;双子座:b;克劳德:C; O3:C; DeepSeek:C。但是正确解决这个问题的解决方案应该是一个,因此在这里杀死了大型模型。这主要是因为问题包含图片,其中包含框架,虚线,箭头和汉字的组合。该模型将无法识别图像,这意味着他们仍然有“查看图片和说话”的空间。而且,由于结局中更加困难的问题,许多大型模型并没有完全获胜,并且经常错过证明过程,或者减少并不严格,这意味着需要加强细节。当涉及到中国的多项选择和阅读问题的两个部分时,大型模型几乎是“学术领域”,得分很高。但是,由于写作太严格,单词很冷,文章中的单词数量不符合标准(少于800个单词或超过1,200个单词),因此,一些问题也暴露在写作过程中,因为想法是不正确的,常见的字幕通常以形式出现。在书面上,这样的单词不够准确,句子略有不变,但是总体情况非常接近完美。在以下问题中,正确的答案应为C。大型模型的答案如下:beanbao:c;双子座:c;克劳德:D; O3:D; DeepSeek:D。最后,就文科而言,大型模型之间区域的差异更为明显。当外国大型模型提出政治和历史问题时,他们通常不了解经过测试的内容,并且对中国的知识点并不是很“冷”。在地理问题方面,最困难的事情是研究统计图和地形图,您应该准确地从地图中提取信息,然后对其进行研究。以上是对本综述的全面评论。除了审查今年进入国内大学的入学外,这些“参与者”还参与在第二次参加印度技术学院的第二次YU考试中 - JEE Advanced。每年数以百万计的人参加考试的第一阶段,前25万名候选人可以在第二阶段前进。它分为两场比赛,每场都有3个小时,并研究了数学,物理和化学的三个主题。该问题以图片形式显示,重点是多模式处理能力和模型的总体推理。所有这些问题都是客观的问题,每个问题都是样本5次,严格按照JEE审查规则进行评分 - 分数将正确得分,如果回答不正确,则分数将被扣除,并且不涉及格式评分标准。比较所有印度人候选人的分数,这表明第一名是332分,第10位将终止317分。值得注意的是,Beanbao和Gemini有能力进入印度的前十名:双子座在物理和化学主题中徒劳无功,而Beanbao通过5个数学学科的例子实现了完整的比赛。这是怎么做的?与去年一流大学的在线和离线水平相比,总的来说,大型模型在今年的大学入学评论问题中的表现已大大提高。那么他们如何提高自己的能力呢?让Bean Bag赢得最多的单个项目编号,以了解这一点。 Dubao Big Model 1.6系列是由Bontedance Seed Team推出的新一代通用模型,结合了多模式和深层推理能力。改进您的技术亮点可以归因于三个技巧。第一个技巧:种子构造能力的多模式融合和256K长的上下文1.6继续在稀疏MOE(混合专家模型)领域的种子1.5的技术积累,并使用23B激活参数和230b总P实践前的芳香尺寸。它的预训练过程实现了融合和延长支撑的多模式能力:阶段1:纯文本预训练。基于网页,书籍,论文,代码和其他数据作为培训的基础,它通过清洁数据,过滤,减少和征服技术与策略和模型相结合来改善数据质量和密度。第二阶段:多模式与连续训练(MMCT)混合(MMCT)将进一步增强D密度文本文本的知识和识别,增加主题,代码和识别数据的比例,同时引入视觉模态数据,以将其与高质量的文本混合。第3阶段:连续训练(LONGCT)的漫长背景通过发短信的数据来逐渐扩大模型顺序的长度,从而将最大支持长度从32K增加到256K。通过继续优化模型架构,培训和基础算法,SEED1.6的性能与种子1.5的基础相比,当参数量表接近时,基础模型显着改善,将基础用于后续训练任务。此举努力在提高准确性方面发挥了作用,例如在科学应用中了解中文阅读,英语空白和全面的OneSsemsquion,因为它们通常涉及长文本和上下文理解。第二个技巧:多模式融合思考的能力。 SEED1.6认为,延续了多个阶段的RFT(强化反馈培训)和RL(强化研究)迭代优化种子1.5思维的方法。每个RL旋转都有一个起点,最好的答案是通过多维奖励模型过滤的。与前几代相比,升级点包括:扩大计算强度和高质量的数据大小(涵盖数学,代码,拼图等领域);改善复杂问题的思考时间,VLM功能的深层集成,并提供明确的能力模型,以理解视觉效果;引入奉献精神的一致性技术,扩展模型功能而没有进一步的培训,例如,在超越AIME的高难度测试集中,推理标记增加了8分,并且性能代码性能明显优化。该功能直接对应于涉及大学入学评论的图表和公式的问题,例如数学的证明几何,物理电路图的评估,地理和其他高线解释等;它很快找到了基本参数,并在解决问题方面存在问题,以避免由于缺乏单局信息而引起的误解。第三个技巧:Autocot解决了跌倒的问题。深思熟虑取决于长床(长思维链)来增强推理的能力,但很容易导致“崩溃” - 产生大量无效令牌并增加推理的负担。因此,种子1.6-autocot提出了“动态思维能力”,提供了三种模式:全心全意,无意识和发人深省,并在RL训练中引入新的奖励功能(惩罚适当思维的下降和奖励),以实现动态压缩的cot长度。在实际试验中:在中等的非门诊任务(例如MMLU,MMLU Pro)中,COT触发率与任务难度呈正相关(MMLU触发率为37%,MMLU Pro触发率为70%);在复杂的任务(例如AIME)中,COT触发率为100%,效果与Seed1.6-Fullcot相当,证实了自适应思维的长COT推断优势的维护。以上就是为什么杜巴能够站起来回顾今年大学入学评论的整个主题的原因。但是除此之外,还有一些值得谈论的影响因素。正如我们今天提到的,阅读照片提供了巨大的比例关于化学和生物学的问题,但是由于非官方图像的清晰度不足,大多数大型模型的表现不佳。但是,GEMINI2.5-PRO-0605具有出色的多模式能力,尤其是在化学领域。但是,最近,在使用了更清晰的大学入学审查问题照片之后,Byteseed团队排练了生物学和化学的主题,对MG MGA图片组合中的图片有很高的要求。结果表明,种子1.6认为的总得分增加了约30分(科学总分为676)。交错图形和文本的示例。它表明,全模式推理(结合文本和图像)可以显着释放该模型的潜力和值得将来进行深入探索的方向。那么,您目前如何看待大型模型之战的结果呢?欢迎大家使用真实的问题尝试它们,并在Comm中留下您的感受Ent区域〜